After drifting away into some niche topics in my previous post, I’m back to my “hobby@work” – PowerCLI scripting!
Anybody who ever worked with block storage (so FC or iSCSI) sooner or later came across the task of “managing” storage path configuration in the environment.
Whether you troubleshoot some performance issues (and storage is one of the “usual suspects”, right?) or you’re migrating to new SAN and want to verify the settings, or maybe you are top-notch IT professional
(like we all are 😉 ) that just does this kind of checks on regular basis – you don’t want to do it manually with vSphere/Web Client.
PowerCLI is the obvious answer and it is really easy to report these settings with get-scsilun and get-scsilunpath cmdlets. There is a great many scripts of this kind on the Web and once you get “per device” output you can easily(?) manipulate it with Excel or any other spreadsheet application you prefer.
Well, I’m not good with Excel at all and whenever I learn the basic moves around it, they introduce a new version and a new “learning curve” starts for me, so I needed my “pathfinder” script to do a little more than just “basic reporting”. I wanted things like co-relating canonical name (t10, naa, eui) with “human friendly” datastore name, I wanted extra information like number of paths that were disabled by administrator or which PSP has been selected for the device and most of all I wanted path configurations that “stand-out” to be visible immediately after I open the CSV (what else 😉 ) report, with no additional filtering in Excel required.
Luckily Gods of PowerShell blessed us with sort-object cmdlet which makes writing such script not really difficult.
Without much further ado – here it is:
#requires -version 2
<#
.SYNOPSIS
Script will report discrepancies in storage paths configuration for all hosts in given VI Container (typically a cluster).
The raport is saved in CSV format, to the folder the script was invoked from, with filename <timestamp>_storage-paths_report_for_$($LocationName)_vi-container.csv
.DESCRIPTION
Script first enumerates all responding vmhosts in VI container (cluster), next names and canonical names of datastores
for the same container are enumerated, with exception for local and NAS datastores
(so only FC and iSCSI datastore paths are taken into consideration).
Subsequently for each vmhost SCSI luns are retrieved, excluding local and non-disk (e.g. cdrom) devices.
For each SCSI lun total number of paths together with number of active and disabled paths is calculated, also information
like PSP used and canonical name (to later match with datastore) is retrieved.
Array containing all paths information for all vmhosts in given container is then sorted to contain only entries with
unique canonical names and path configuration.
Before exporting to CSV this array is searched for canonical names to pin-point datastores that have different
pathing among vmhosts.
Final report is saved in <timestamp>_storage-paths_report_for_$($LocationName)_vi-container.csv file.
.PARAMETER vCenterServer
Mandatory parameter indicating vCenter server to connect to (FQDN or IP address)
.PARAMETER LocationName
Mandatory parameter indicating name of VI Container where storage paths need to be checked.
Typically a vmhost cluster name, but datacenter or folder names are also accepted, even though the script
will produce false positives if you have different datastore sets per cluster in your datacenter.
.EXAMPLE
check-storage-paths.ps1 -vCenterServer vcenter.seba.local -LocationName Production-Cluster
To generate report about storage paths for a host cluster provide cluster name.
.EXAMPLE
check-storage-paths.ps1 -vcenter 10.0.0.1 -location DR-datacenter
To generate report about storage paths for whole datacenter provide datacenter name (and go for lunch ;) ).
.EXAMPLE
check-storage-paths.ps1
Script will interactively ask for both mandatory parameters
#>
[CmdletBinding()]
Param(
[Parameter(Mandatory=$True,Position=1)]
[string]$vCenterServer,
[Parameter(Mandatory=$True, Position=2)]
[string]$LocationName
)
Function Write-And-Log {
[CmdletBinding()]
Param(
[Parameter(Mandatory=$True,Position=1)]
[string]$LogFile,
[Parameter(Mandatory=$True,Position=2)]
[string]$line,
[Parameter(Mandatory=$False,Position=3)]
[int]$ErrorCount=0,
[Parameter(Mandatory=$False,Position=4)]
[string]$type="terse"
)
$LogEntry = (Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + $line
$ui = (Get-Host).UI.RawUI
if ($ErrorCount) {
$ui.ForegroundColor = "red"
$LogEntry = ">>> ERROR <<< " + $LogEntry
Write-Output $LogEntry
$LogEntry | Out-File $LogFile -Append
}
else {
$ui.ForegroundColor = "green"
if ($type -ne "terse"){
Write-Output $LogEntry
$LogEntry | Out-file $LogFile -Append
}
else {
Write-Output $LogEntry
}
}
$ui.ForegroundColor = "white"
}
#variables
$ScriptRoot = Split-Path $MyInvocation.MyCommand.Path
$StartTime = Get-Date -Format "yyyyMMddHHmmss_"
$csvoutfile = $ScriptRoot + "" + $StartTime+ "storage-paths_report_for_$($LocationName)_vi-container.csv"
$logfilename = $ScriptRoot + "" + $StartTime + "check-storage-paths.log"
$transcriptfilename = $ScriptRoot + "" + $StartTime + "check-storage-paths_Transcript.log"
$all_devices_path_info = @()
$total_errors = 0
$total_datastores = 0
$total_vmhosts = 0
$index_vmhosts = 0
$index_datastores = 0
#start PowerShell transcript... or don't start it ;)
#Start-Transcript -Path $transcriptfilename
#load PowerCLI snap-in
$vmsnapin = Get-PSSnapin VMware.VimAutomation.Core -ErrorAction SilentlyContinue
$Error.Clear()
if ($vmsnapin -eq $null)
{
Add-PSSnapin VMware.VimAutomation.Core
if ($error.Count -eq 0)
{
write-and-log $logfilename "PowerCLI VimAutomation.Core Snap-in was successfully enabled." 0 "full"
}
else
{
write-and-log $logfilename "Could not enable PowerCLI VimAutomation.Core Snap-in, exiting script" 1 "full"
Exit
}
}
else
{
write-and-log $logfilename "PowerCLI VimAutomation.Core Snap-in is already enabled" 0 "full"
}
#check PowerCLI version
if (($vmsnapin.Version.Major -gt 5) -or (($vmsnapin.version.major -eq 5) -and ($vmsnapin.version.minor -ge 1))) {
#assume everything is OK at this point
$Error.Clear()
#connect vCenter from parameter
Connect-VIServer -Server $vCenterServer -ErrorAction SilentlyContinue | Out-Null
#execute only if connection successful
if ($error.Count -eq 0){
#measuring execution time is really hip these days
$stop_watch = [Diagnostics.Stopwatch]::StartNew()
#use previously defined function to inform what is going on, anything else than "terse" as last argument will cause the message to be written both in logfile and to screen
Write-And-Log $logfilename "vCenter $vCenterServer successfully connected" $error.count "full"
#get all responding vmhosts in $LocationName
$vmhosts_in_location = get-vmhost -location $LocationName -ErrorAction SilentlyContinue | where-object { ($_.connectionstate -eq "connected") -or ($_.connectionstate -eq "maintenance") }
#check against typo in $LocationName
if ($error.Count -eq 0){
#get names and canonical names of all available, non-local, non-NAS datastores in $LocationName
$datastore_names_in_location = $vmhosts_in_location | get-datastore | where-object { ($_.state -eq "Available") -and ( -not ($_.ExtensionData.Info.Nas)) -and ($_.ExtensionData.Summary.MultipleHostAccess) } | select-object @{N="DatastoreName"; E={@($_.Name)}}, @{N="CanonicalName"; E={@($_.ExtensionData.Info.VMFS.Extent[0].DiskName)}}
#only if we've found some vmhosts AND datastores
if ($vmhosts_in_location -and $datastore_names_in_location){
#just initialize counters
$total_vmhosts = $vmhosts_in_location.count
$total_datastores = $datastore_names_in_location.count
foreach ($vmhost in $vmhosts_in_location) {
#all OK here
$error.Clear()
#display nice progress bar in PowerCLI window
write-progress -Activity "Gathering storage paths data for vi-container $LocationName" -Status "Percent complete $("{0:N2}" -f (($index_vmhosts / $total_vmhosts) * 100))%" -PercentComplete (($index_vmhosts / $total_vmhosts) * 100) -CurrentOperation "Checking vSphere host: $($vmhost.name)"
#get LUNs for vSphere host
$vmhostSCSILuns = $vmhost | get-ScsiLun -LunType "disk" | where-object {(-not $_.IsLocal)}
#unlikely to happen that datastore is not visible from all hosts (when in same cluster), but I prefer to check it...
if ($vmhostSCSILuns.count -eq $total_datastores) {
#most of the magic happens here, retrieving CanonicalNames and counting paths (total, active, disabled) for each device
$vmhost_path_entries = $vmhostSCSILuns | select-object @{N="CanonicalName"; E={@($_.CanonicalName)}}, @{N="VMHostName"; E={@($_.VMHost.Name)}}, @{N="NumFCPaths"; E={@(@($_ | get-scsilunpath).count)}}, @{N="NumActiveFCPaths"; E={@(@($_ | get-scsilunpath | where-object { $_.state -eq "active" }).count) }}, @{N="NumDisabledFCPaths"; E={@(@($_ | get-scsilunpath | where-object { $_.state -eq "disabled" }).count) }}, @{N="PSP"; E={@($_.MultiPathPolicy)}}
#just creating report structure
foreach ($vmhost_path_entry in $vmhost_path_entries) {
$single_device_path_info = New-Object PSObject
$datastore_name = $($datastore_names_in_location | where-object {$_.CanonicalName -eq $vmhost_path_entry.CanonicalName}).DatastoreName
$single_device_path_info | Add-Member -Name "DatastoreName" -Value $datastore_name -MemberType NoteProperty
$single_device_path_info | Add-Member -Name "CanonicalName" -Value $vmhost_path_entry.CanonicalName -MemberType NoteProperty
$single_device_path_info | Add-Member -Name "VMHostName" -Value $vmhost_path_entry.VMHostName -MemberType NoteProperty
$single_device_path_info | Add-Member -Name "NumFCPaths" -Value $vmhost_path_entry.NumFCPaths -MemberType NoteProperty
$single_device_path_info | Add-Member -Name "NumActiveFCPaths" -Value $vmhost_path_entry.NumActiveFCPaths -MemberType NoteProperty
$single_device_path_info | Add-Member -Name "NumDisabledFCPaths" -Value $vmhost_path_entry.NumDisabledFCPaths -MemberType NoteProperty
$single_device_path_info | Add-Member -Name "PSP" -Value $vmhost_path_entry.PSP -MemberType NoteProperty
$single_device_path_info | Add-Member -Name "Status" -Value "OK" -MemberType NoteProperty
$all_devices_path_info += $single_device_path_info
}
write-and-log $logfilename "vSphere host $($vmhost.name) checked, moving on" 0 "terse"
}
else {
write-and-log $logfilename "vSphere host $($vmhost.name) is not able to access all shared datastores in vi-container $ClusterName !!!" 1 "full"
$total_errors++
}
$index_vmhosts++
}
#this check is for strange situation where none of the hosts can access all datastores
if ($all_devices_path_info){
#sort path information array to leave unique entries only
$all_devices_path_info_sorted = $all_devices_path_info | sort-object CanonicalName, NumFCPaths, NumActiveFCPaths, NumDisabledFCPaths -Unique
#this copy will be used for final report, if there are path misconfigurations it will have more entries than above array
$all_devices_path_info_final = $all_devices_path_info_sorted
#the array is sorted, so we only need to point out duplicate CanonicalNames
foreach ($datastore_name in $datastore_names_in_location){
#another progress bar, but it will probably flash so fast you won't even notice
write-progress -Activity "Checking storage paths consistency for vi-container $LocationName" -Status "Percent complete $("{0:N2}" -f (($index_datastores / $total_datastores) * 100))%" -PercentComplete (($index_datastores / $total_datastores) * 100) -CurrentOperation "Checking Datastore: $($datastore_name.DatastoreName)"
$different_paths = $all_devices_path_info_sorted | where-object {$_.CanonicalName -eq $datastore_name.CanonicalName}
#if there is more than one canonical name, we set the status to NOK, also we go back to "raw data" to retrieve all hosts that have given pathing (there can be more than one!)
if ($different_paths.count -gt 1) {
foreach ($different_path in $different_paths){
$different_hosts = $all_devices_path_info | Where-Object {($_.CanonicalName -eq $different_path.CanonicalName) -and ($_.NumFCPaths -eq $different_path.NumFCPaths) -and ($_.NumActiveFCPaths -eq $different_path.NumActiveFCPaths) -and ($_.NumDisabledFCPaths -eq $different_path.NumDisabledFCPaths) }
foreach ($different_host in $different_hosts) {
$different_host.Status = "NOK"
$all_devices_path_info_final += $different_host
}
}
write-and-log $logfilename "Non-equal number of paths to datastore $($datastore_name.DatastoreName) among hosts in vi-container $LocationName" 1 "full"
$total_errors++
}
else {
$different_paths.VMHostName = "AllVMHosts"
write-and-log $logfilename "Datastore $($datastore_name.DatastoreName) looks OK, moving on" 0 "terse"
}
$index_datastores++
}
#export to CSV
$all_devices_path_info_final = $all_devices_path_info_final | Sort-Object CanonicalName, VMHostName -Unique
$all_devices_path_info_final | Export-Csv -Path $csvoutfile -NoTypeInformation
Write-And-Log $logfilename "Report created in $($csvoutfile)" $total_errors "full"
}
else{
Write-And-Log $logfilename "Not a single host can access all datastores in $LocationName vi container (empty report)" 1 "full"
$total_errors++
}
}
else{
Write-And-Log $logfilename "No available hosts/datastores found in $LocationName vi container" 1 "full"
$total_errors++
}
}
else {
Write-And-Log $logfilename "Error resolving vi container $LocationName name" $error.count "full"
$total_errors += $error.count
}
$stop_watch.Stop()
$elapsed_seconds = ($stop_watch.elapsedmilliseconds)/1000
#farewell message before disconnect
Write-And-Log $logfilename "Total of $total_vmhosts hosts and $total_datastores datastores checked in $("{0:N2}" -f $elapsed_seconds)s, $total_errors ERRORS reported, exiting" $total_errors "full"
#disconnect vCenter
Disconnect-VIServer -Confirm:$false -Force:$true
}
else{
Write-And-Log $logfilename "Error connecting vCenter server $vCenterServer, exiting" $error.count "full"
}
}
else {
write-and-log $logfilename "This script requires PowerCLI 5.1 or greater to run properly" 1 "full"
}
#if you started the transcript, it's a good moment to stop it now.
#Stop-Transcript
I know it looks lengthy, but most of this “code” is to make it foolproof and chatty, or display progress bars and fancy counters ;).
I will try to focus on just a few lines, where all the “magic” happens.
First of all – I made an assumption that for the given VI container (typically a host cluster) all datastores are configured with “full-mesh” access, so each host can access all datastores. If you happen to have a set-up where there is a single host (in cluster) with some “extra” datastore (to copy some vms or whatever from different clusters, for example), this script will report it is as error for all vSphere hosts, except “the chosen one”. So if you have such config, just disable the condition in Line 188 (fix it to $true or something like that 😉 ).
Please note that this condition will kick-in also in situations where you have datastores that span multiple LUNs (more devices than datastores!) or if your vSphere hosts can see LUNs that are not VMFS datastores (also RDMs!). If at this moment you think this check gives you too much trouble already – fix it to $true now! ;).
I will also like to stress-out that I was always using this script for host clusters – just because this is a typical setup to me, to have uniform SAN zoning for a cluster. If you want, you can also (try to) use this script for the whole datacenter or folder of hosts/clusters/datacentres, just remember that above conditions still apply – if SAN zoning is not uniform between clusters you will get lots of “false positives” (unless you disable the check in Line 188).
Line 163 is where I gather the vSphere hosts that are connected or in maintenance mode, cause we can only report from hosts that are responsive.
In Line 169 I filter out local and NAS datastores (cause path configuration doesn’t apply to them) and create an array containing (datastore name, canonical name) pairs that will help me to resolve datastore names from canonical names later on. There is small caveat here, because to retrieve canonical name of device I’m using only the first element of ExtensionData.Info.VMFS.Extent array. That’s no big deal for me because of (in)famous check in Line 188, but if you have VMFS datastores that span multiple extents, you (again) need to fix this check to $true. The script will not be able to resolve datastore names for these additional extents, but it will still report discrepancies at device level, only with empty datastore name. (Do you still have multiple extent datastores? Really?)
Line 193 is the place where script gathers actual path configuration. I’m counting total number of paths, together with number of active and disabled ones. In a perfect world all hosts should have all these numbers equal. If there are discrepancies between number of paths that hosts can see – there is most likely problem with SAN zoning. If number of active paths is different between hosts, it can be either SAN issue or different PSP selected for the device (that’s why I also retrieve the latter).
I was also trying to fit “datastore name resolution” in Line 193, but somehow couldn’t get “nested $_ statements” working for me, that’s why I ended up with creating “path entries” for each device between Line 196 and Line 207. You might not like it, but I wasn’t able to figure-out anything more elegant, luckily these are simple operations that do not waste much time.
Line 224 is really important, cause all the duplicate “path vectors” are eliminated here, and we end-up with array of unique (canonical name, path-configuration) objects… But this isn’t even the final form of this information! 😉
Now, don’t get confused with what happens between Line 233 and Line 255, cause it is really simple. The script first looks up for duplicate canonical names. If it founds any – it means that the same block device has different path configuration between hosts, so we’ve got “some issues”. If you are lucky there is only one host that “stands-out”, but in worst case scenario each host can have different “path vector” in the fabric (sic!).
Obviously, the script can not decide which configuration is correct (it is still for the human to decide, right?). That’s why between Line 236 and Line 243 the script goes back to “raw data” (meaning: unsorted array), to retrieve entries for all detected path configurations for device in question. It may sound complicated but again, not too much time is wasted for these operations (as I will show you later).
The final result (in CSV report) is that for each block device that has uniform configuration in cluster we get a single entry (with OK status and AllVMHosts as “VMHostName”) and for anything non-uniform, we get a list of all hosts from cluster with path configuration specified for each host. And this is exactly what I wanted to achieve – immediately after opening the report I can see where the issues are (NOK status!) and to which hosts I should go to fix them (once I recognize which of different path configurations is correct B) ).
Here is a example report from my home lab:
"DatastoreName","CanonicalName","VMHostName","NumFCPaths","NumActiveFCPaths","NumDisabledFCPaths","PSP","Status" "deobiSCSI-t1_SmaLL","t10.F405E46494C454254336F4869307D2E485F605D2A7A47697","vmhost01.seba.local","1","1","0","MostRecentlyUsed","NOK" "deobiSCSI-t1_SmaLL","t10.F405E46494C454254336F4869307D2E485F605D2A7A47697","vmhost02.seba.local","2","1","0","Fixed","NOK" "deobiSCSI-t1_SmaLL","t10.F405E46494C454254336F4869307D2E485F605D2A7A47697","vmhost03.seba.local","2","2","0","RoundRobin","NOK" "deobiSCSi-t1_BiG","t10.F405E46494C4542577543524D4E6D295F423F6D257E60386","vmhost01.seba.local","1","1","0","MostRecentlyUsed","NOK" "deobiSCSi-t1_BiG","t10.F405E46494C4542577543524D4E6D295F423F6D257E60386","vmhost03.seba.local","2","1","0","Fixed","NOK" "deobiSCSi-t1_BiG","t10.F405E46494C4542577543524D4E6D295F423F6D257E60386","vmhost02.seba.local","2","1","1","Fixed","NOK" "deobiSCSI-t2","t10.F405E46494C45425930586A5B426D2133533D6D276559434","AllVMHosts","2","1","0","Fixed","OK"
As you can see I’ve got a real mess there, disabled paths, different PSPs configured, there is a lot of “gardening” for me to work on ;).
I would also like to show you a screenshot showing this script in some “real life” action, I hope you understand I had to “anonymize” most of the information 😉
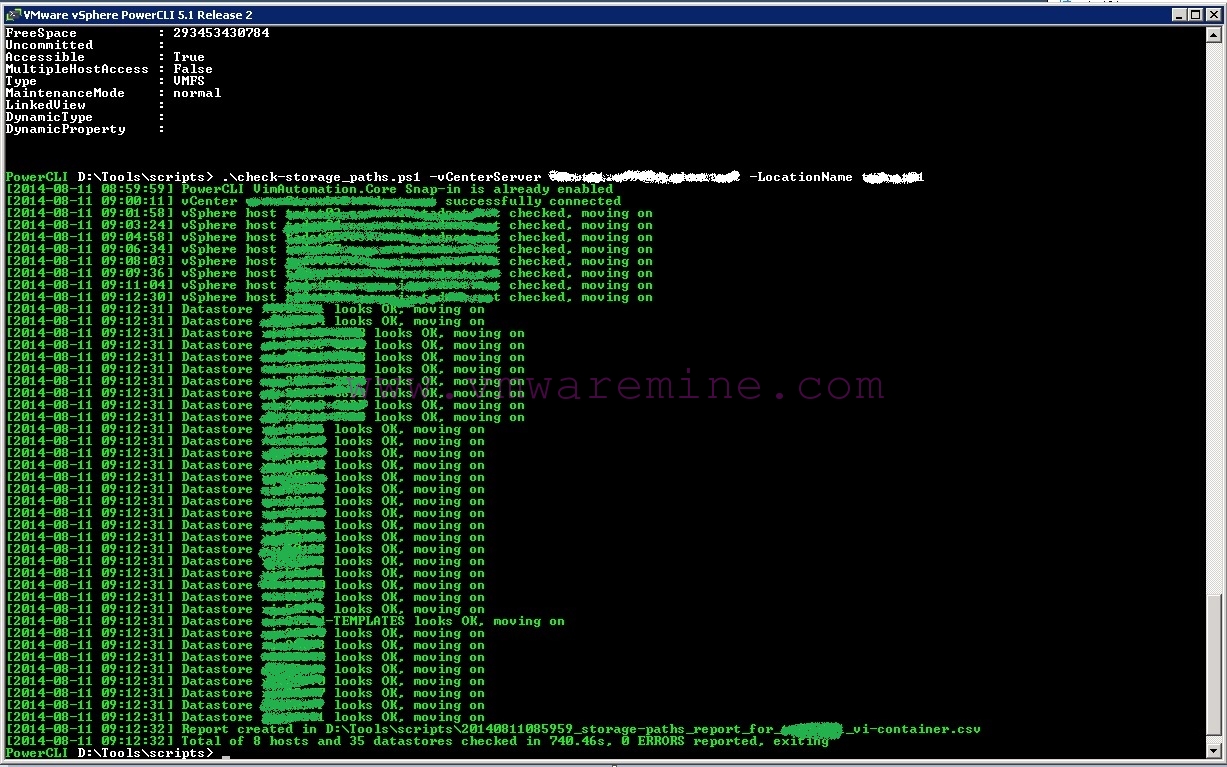
As you can see the report for a cluster with 8 vSphere hosts and 35 (FC) datastores was created in something like 12 and a half minutes. It is not really blistering speed, but the script spends most of the time querying the hosts for LUN and path information. I could probably speed this process up by using PowerCLI views, but… views are something I still need to learn about, cause I don’t feel very comfortable around them ;).
Also the sorting and resolving hosts and datastores part could probably be “coded” better, but it only takes seconds compared to sequence where information is gathered, so I wouldn’t worry too much about it.
A word on explanation on why I decided to create this (datastore name, canonical name) array just to resolve datastore names. Well, initially I was trying to start this script with get-datastore cmdlet to retrieve all datastores from the given VI container (and then pipeline collection of datastores to get-scsilun and get-scsilunpath cmdlets), instead of iterating through vSphere hosts to look for LUNs. If I were successful with that – this “name resolving array” wouldn’t be needed of course.
Unfortunately not only it took longer (as you can see querying a host for LUNs takes about 90 seconds, querying a datastore for luns and paths lasted at least 3 minutes per datastore), but also it just didn’t work for iSCSI luns (get-scsilun cmdlet just got hung with neither output nor errors when provided with a iSCSI datastore as pipeline input – at least in every environment I had opportunity to test this script).
I hope you will find this script useful, but any feedback is welcome 😉
Also – be sociable and share!

This looks like exactly what I needed, unfortunately it fails to produce the csv file at the end with no indication why, just “empty report”. It DOES produce log files.
>>> ERROR <<>> ERROR <<< [2014-12-30 07:03:03] Total of 21 hosts and 90 datastores checked in 543.94s, 22 ERRORS reported, exiting