In my first blog post ever, almost three months ago I shared my good ol’ script for batch deployment of virtual machines.
That script served me well for quite a few years already, but it was somewhat on the crude side of scripting.
It was using new-vm cmdlet sequentially for each line of .csv input and the method of controlling the deployment progress was just a sequence of while loops that tested the status of VMTools in freshly deployed VM.
Not very elegant, but this wasn’t a big issue for me, neither was the sluggishness of synchronous deployment.
I simply used to run this script overnight and if I had any concerns the batch would not complete before I come back to work in the morning, I would just split it into separate .csv-s and start multiple instances of PowerCLI for that.
Once that simple script “went public” I made a commitment to “some people” that I will re-write it to use async tasks (so deploy multiple VMs simultaneously) and I promised to finish that before my summer holiday this year ;).
This was also great opportunity for me to learn more on how to control background jobs, so here we go.
The new script still takes input (VMs to be deployed) from a CSV file which should be saved in script’s working directory, under “hard coded” name of vms2deploy.csv.
Just to remind you, the CSV file should look somewhat like this:
name,template,oscust,cluster,folder,datastorecluster,ip,mask,gw,dns1,dns2 win2k8_01,win2k8-template,win2k8-oscust,ServerCluster,ServerFolder,ServerStorageCluster,10.0.1.16,255.255.255.0,10.0.1.1,10.0.0.32,10.0.0.34 win7_01,win7-template,win7-oscust,VDICluster,VDIFolder,VDIStorageCluster,none,255.255.255.0,10.0.1.1,10.0.0.32,10.0.0.34 Linux01,rhel-template,rhel-oscust,ServerCluster,ServerFolder,ServerStorageCluster,10.0.69.69,255.255.255.0,10.0.1.1,none,10.0.0.34
Fields are still pretty self-explanatory I believe, but I introduced first improvement here already – as you can see for deploying a Linux VM you can (in fact you should) put “none” as value of “dns1” field.
This is because it is impossible to set DNS servers configuration via OS Customization Specification for Linux VMs (there is a check in the script that handles this value properly).
Not much else to comment on here, except maybe “datastorecluster” field – If you’re still not using Datastore Clusters in your environment, you should modify this script to use get-cluster cmdlet instead of get-datastorecluster where necessary (it is only used twice, so this shouldn’t be a big problem 😉 ).
If you do use Datastore Clusters however, remember to turn Storage DRS (SDRS) on.
This is required for initial placement of new VMs on the datastores just like DRS is required for initial placement of new VMs on hosts. If SDRS is not enabled the script will fail miserably (and silently 😉 ).
Many thanks to @KrazieEyes for finding this out and letting me know via Twitter!
Because of this KB script requires PowerCLI 5.5 R1 and because I manipulate OS Customization Specifications during deployment, it needs to be started from 32-bit PowerCLI window…
Well, not anymore – as pointed-out by Shawn Masterson below, VMware did a great job recently and complied 64-bit versions of “OS Customization related” cmdlets, that’s why the condition in Line 371 is fixed to $true now 😉 .
The general workflow for the script is as follows. In step one input is sanitized (empty fields and duplicate VM names are eliminated from CSV file), then script groups VMs to be deployed per host cluster and starts a separate background job (so separate PowerShell process) for each cluster.
I still tend to think in host clusters categories, if you also group your hosts in logical folders (which is actually VMware’s recommendation), I encourage you to modify this script to use -Location instead of -Cluster where necessary.
After dispatching background jobs the only responsibility of “main” script is to pool these jobs every 20 seconds and display overall progress, as usual quite detailed logging is done both for main script and for each background deployment job.
This is how the code looks:
#requires -version 2
<#
.SYNOPSIS
Script automates deployment of multiple vms loaded from pre-defined .csv file
.DESCRIPTION
Script reads input from .csv file (that needs to be saved in script's working directory, under the name of "vms2deploy.csv")
Script will return an error if the file is not found in working directory.
After rudimentary input sanitization (removing lines with empty fields) a separate background job (process) is started for
each unique host cluster found in input.
The scriptblock that defines background job takes care of asynchronous creation of requested VMs (clone from template).
To not overload the cluster number of VMs being deployed at any given moment is smaller than number of active vmhosts in cluster.
After VM is deployed scriptblock powers it on to start OS Customization process.
Last part of deploy scriptblock is to search vCenter events for successful or failed customization completions.
Background job exits when all powered on VMs completed OS Customization (no matter successfully or not) or when pre-defined
time-out elapses.
.PARAMETER vCenterServer
Mandatory parameter indicating vCenter server to connect to (FQDN or IP address)
.EXAMPLE
ultimate_deploy.ps1 -vCenterServer vcenter.seba.local
vCenter Server indicated as FQDN
.EXAMPLE
ultimate_deploy.ps1 -vcenter 10.0.0.1
vCenter Server indicated as IP address
.EXAMPLE
ultimate_deploy.ps1
Script will interactively ask for mandatory vCenterServer parameter
#>
[CmdletBinding()]
Param(
[Parameter(Mandatory=$True,Position=1)]
[ValidateNotNullOrEmpty()]
[string]$vCenterServer
)
Function Write-And-Log {
[CmdletBinding()]
Param(
[Parameter(Mandatory=$True,Position=1)]
[ValidateNotNullOrEmpty()]
[string]$LogFile,
[Parameter(Mandatory=$True,Position=2)]
[ValidateNotNullOrEmpty()]
[string]$line,
[Parameter(Mandatory=$False,Position=3)]
[int]$Severity=0,
[Parameter(Mandatory=$False,Position=4)]
[string]$type="terse"
)
$timestamp = (Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] "))
$ui = (Get-Host).UI.RawUI
switch ($Severity) {
{$_ -gt 0} {$ui.ForegroundColor = "red"; $type ="full"; $LogEntry = $timestamp + ":Error: " + $line; break;}
{$_ -eq 0} {$ui.ForegroundColor = "green"; $LogEntry = $timestamp + ":Info: " + $line; break;}
{$_ -lt 0} {$ui.ForegroundColor = "yellow"; $LogEntry = $timestamp + ":Warning: " + $line; break;}
}
switch ($type) {
"terse" {Write-Output $LogEntry; break;}
"full" {Write-Output $LogEntry; $LogEntry | Out-file $LogFile -Append; break;}
"logonly" {$LogEntry | Out-file $LogFile -Append; break;}
}
$ui.ForegroundColor = "white"
}
#a scary scriptblock to feed background jobs
$deployscriptblock = {
param($vCS, $cred, $vms, $log, $progress)
#simple helper object to track job progress, we will dump it to $clustername-progres.csv for the parent process to read every minute
$job_progress = New-Object PSObject
$job_progress | Add-Member -Name "PWROK" -Value 0 -MemberType NoteProperty
$job_progress | Add-Member -Name "PWRFAIL" -Value 0 -MemberType NoteProperty
$job_progress | Add-Member -Name "DPLFAIL" -Value 0 -MemberType NoteProperty
$job_progress | Add-Member -Name "CUSTSTART" -Value 0 -MemberType NoteProperty
$job_progress | Add-Member -Name "CUSTOK" -Value 0 -MemberType NoteProperty
$job_progress | Add-Member -Name "CUSTFAIL" -Value 0 -MemberType NoteProperty
$job_progress | Export-Csv -Path $progress -NoTypeInformation
#scriptblock is started as separate PS (not PowerCLI!), completely autonomous process, so we really need to load the snap-in
$vmsnapin = Get-PSSnapin VMware.VimAutomation.Core -ErrorAction SilentlyContinue
$Error.Clear()
if ($vmsnapin -eq $null){
Add-PSSnapin VMware.VimAutomation.Core
if ($error.Count -ne 0){
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + "Error: Loading PowerCLI" | out-file $log -Append
exit
}
}
#and connect vCenter
connect-viserver -server $vCS -Credential $cred 2>&1 | out-null
if ($error.Count -eq 0){
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: vCenter $vCS successfully connected" | out-file $log -Append
#array to store cloned OS customizations that we need to clean-up once script finishes
$cloned_2b_cleaned = @()
#hash table to store new-vm async tasks
$newvm_tasks = @{}
#this is needed as timestamp for searching the logs for customization events at the end of this scriptblock
$start_events = get-date
$started_vms = @()
#array of customization status values and a timeout for customization in seconds (it is exactly 2hrs, feel free to reduce it)
$Customization_In_Progress = @("CustomizationNotStarted", "CustomizationStarted")
[int]$timeout_sec = 7200
#after we sanitized input, something must be there
$total_vms = $vms.count
#so I'm not afraid to reach for element [0] of this array
$vmhosts = get-vmhost -location $vms[0].cluster -state "connected"
$total_hosts = $vmhosts.count
$batch = 0
#split vms to batches for deployment, each batch has $total_hosts concurrent deployments (so a single host deploys only one vm at a time)
while ($batch -lt $total_vms){ #scan array until we run out of vms to deploy
$index =0
while ($index -lt $total_hosts){ #in batches equal to number of available hosts
if ($vms[($batch + $index)].name) { #check if end of array
if (!(get-vm $vms[($batch + $index)].name -erroraction 0)){ #check if vm name is already taken
#if "none" detected as IP address, we do not set it via OSCustomizationSpec, whatever is in template will be inherited (hopefully DHCP)
if ($vms[($batch + $index)].ip -match "none"){
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: No IP config for $($vms[($batch + $index)].name) deploying with DHCP!" | out-file $log -Append
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: Starting async deployment for $($vms[($batch + $index)].name)" | out-file $log -Append
$newvm_tasks[(new-vm -name $($vms[($batch + $index)].name) -template $(get-template -name $($vms[($batch + $index)].template)) -vmhost $vmhosts[$index] -oscustomizationspec $(get-oscustomizationspec -name $($vms[($batch + $index)].oscust)) -datastore $(get-datastorecluster -name $($vms[($batch + $index)].datastorecluster)) -diskstorageformat thin -location $(get-folder -name $($vms[($batch + $index)].folder)) -RunAsync -ErrorAction SilentlyContinue).id] = $($vms[($batch + $index)].name)
#catch new-vm errors - if any
if ($error.count) {
$error[0].exception | out-file $log -Append
$job_progress.DPLFAIL++
$error.clear()
}
}
else {
#clone the "master" OS Customization Spec, then use it to apply vm specific IP configuration (for 1st vNIC ONLY!)
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: Cloning OS customization for $($vms[($batch + $index)].name)" | out-file $log -Append
$cloned_oscust = Get-OSCustomizationSpec $vms[($batch + $index)].oscust | New-OSCustomizationSpec -name "$($vms[($batch + $index)].oscust)_$($vms[($batch + $index)].name)"
#for Linux systems you can not set DNS via OS Customization Spec, so set it to "none"
if ($vms[($batch + $index)].dns1 -match "none") {
Set-OSCustomizationNicMapping -OSCustomizationNicMapping ($cloned_oscust | Get-OscustomizationNicMapping) -Position 1 -IpMode UseStaticIp -IpAddress $vms[($batch + $index)].ip -SubnetMask $vms[($batch + $index)].mask -DefaultGateway $vms[($batch + $index)].gw | Out-Null
}
else {
Set-OSCustomizationNicMapping -OSCustomizationNicMapping ($cloned_oscust | Get-OscustomizationNicMapping) -Position 1 -IpMode UseStaticIp -IpAddress $vms[($batch + $index)].ip -SubnetMask $vms[($batch + $index)].mask -DefaultGateway $vms[($batch + $index)].gw -Dns $vms[($batch + $index)].dns1,$vms[($batch + $index)].dns2 | Out-Null
}
#we need to keep track of these cloned OSCustomizationSpecs for the clean-up before we exit
$cloned_2b_cleaned += $cloned_oscust
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: Starting async deployment for $($vms[($batch + $index)].name)" | out-file $log -Append
$newvm_tasks[(new-vm -name $($vms[($batch + $index)].name) -template $(get-template -name $($vms[($batch + $index)].template)) -vmhost $vmhosts[$index] -oscustomizationspec $cloned_oscust -datastore $(get-datastorecluster -name $($vms[($batch + $index)].datastorecluster)) -diskstorageformat thin -location $(get-folder -name $($vms[($batch + $index)].folder)) -RunAsync -ErrorAction SilentlyContinue).id] = $($vms[($batch + $index)].name)
#catch new-vm errors - if any
if ($error.count) {
$error[0].exception | out-file $log -Append
$job_progress.DPLFAIL++
$error.clear()
}
}
}
else {
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Error: VM $($vms[($batch + $index)].name) already exists! Skipping" | out-file $log -Append
}
$index++
}
else {
$index = $total_hosts #end of array, no point in looping.
}
}
#track the progress of async tasks
$running_tasks = $newvm_tasks.count
#exit #debug
while($running_tasks -gt 0){
$Error.clear()
get-task | %{
if ($newvm_tasks.ContainsKey($_.id)){ #check if deployment of this VM has been initiated above
if($_.State -eq "Success"){ #if deployment successful - power on!
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: $($newvm_tasks[$_.id]) deployed! Powering on" | out-file $log -Append
$started_vms += (Get-VM -name $newvm_tasks[$_.id] | Start-VM -confirm:$false -ErrorAction SilentlyContinue)
if ($error.count) { $job_progress.PWRFAIL++ }
else {$job_progress.PWROK++}
$newvm_tasks.Remove($_.id) #and remove task from hash table
$running_tasks--
}
elseif($_.State -eq "Error"){ #if deployment failed - only report it and remove task from hash table
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Error: $($newvm_tasks[$_.id]) NOT deployed! Skipping" | out-file $log -Append
$newvm_tasks.Remove($_.id)
$job_progress.PWRFAIL++
$running_tasks--
}
}
}
#and write it down for parent process to display
$job_progress | Export-Csv -Path $progress -NoTypeInformation
Start-Sleep -Seconds 10
}
$batch += $total_hosts #skip to next batch
}
Start-Sleep -Seconds 10
#this is where real rock'n'roll starts, searching for customization events
#there is a chance, not all vms power-on successfully
$started_vms = $started_vms | where-object { $_.PowerState -eq "PoweredOn"}
#but if they are
if ($started_vms){
#first - initialize helper objects to track customization, we assume customization has not started for any of successfully powered-on vms
#exit #debug
$vm_descriptors = New-Object System.Collections.ArrayList
foreach ($vm in $started_vms){
$obj = "" | select VM,CustomizationStatus,StartVMEvent
$obj.VM = $vm
$obj.CustomizationStatus = "CustomizationNotStarted"
$obj.StartVMEvent = Get-VIEvent -Entity $vm -Start $start_events | where { $_ -is "VMware.Vim.VmStartingEvent" } | Sort-object CreatedTime | Select -Last 1
[void]($vm_descriptors.Add($obj))
}
#timeout from here
$start_timeout = get-date
#now that's real mayhem - scriptblock inside scriptblock
$continue = {
#we check if there are any VMs left with customization in progress and if we didn't run out of time
$vms_in_progress = $vm_descriptors | where-object { $Customization_In_Progress -contains $_.CustomizationStatus }
$now = get-date
$elapsed = $now - $start_timeout
$no_timeout = ($elapsed.TotalSeconds -lt $timeout_sec)
if (!($no_timeout) ){
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Error: Timeout waiting for customization! Manual cleanup required! Exiting..." | out-file $log -Append
}
return ( ($vms_in_progress -ne $null) -and ($no_timeout)) #return $true or $false to control "while loop" below
}
#loop searching for events
while (& $continue){
foreach ($vmItem in $vm_descriptors){
$vmName = $vmItem.VM.name
switch ($vmItem.CustomizationStatus) {
#for every VM filter "Customization Started" events from the moment it was last powered-on
"CustomizationNotStarted" {
$vmEvents = Get-VIEvent -Entity $vmItem.VM -Start $vmItem.StartVMEvent.CreatedTime
$startEvent = $vmEvents | where { $_ -is "VMware.Vim.CustomizationStartedEvent"}
if ($startEvent) {
$vmItem.CustomizationStatus = "CustomizationStarted"
$job_progress.CUSTSTART++
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: OS Customization for $vmName started at $($startEvent.CreatedTime)" | out-file $log -Append
}
break;}
#pretty much same here, just searching for customization success / failure)
"CustomizationStarted" {
$vmEvents = Get-VIEvent -Entity $vmItem.VM -Start $vmItem.StartVMEvent.CreatedTime
$succeedEvent = $vmEvents | where { $_ -is "VMware.Vim.CustomizationSucceeded" }
$failedEvent = $vmEvents | where { $_ -is "VMware.Vim.CustomizationFailed"}
if ($succeedEvent) {
$vmItem.CustomizationStatus = "CustomizationSucceeded"
$job_progress.CUSTOK++
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: OS Customization for $vmName completed at $($succeedEvent.CreatedTime)" | out-file $log -Append
}
if ($failedEvent) {
$vmItem.CustomizationStatus = "CustomizationFailed"
$job_progress.CUSTFAIL++
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Error: OS Customization for $vmName failed at $($failedEvent.CreatedTime)" | out-file $log -Append
}
break;}
}
}
$job_progress | Export-Csv -Path $progress -NoTypeInformation
Start-Sleep -Seconds 10
}
}
#we've got no loose ends at the moment (well, except for timeouts but... tough luck)
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Info: Cleaning-up cloned OS customizations" | out-file $log -Append
$cloned_2b_cleaned | Remove-OSCustomizationSpec -Confirm:$false
}
else{
(Get-Date -Format ("[yyyy-MM-dd HH:mm:ss] ")) + ":Error: vCenter $vCS connection failure" | out-file $log -Append
}
}
#constans
#variables
$ScriptRoot = Split-Path $MyInvocation.MyCommand.Path
$StartTime = Get-Date -Format "yyyyMMddHHmmss_"
$csvfile = $ScriptRoot + "\" + "vms2deploy.csv"
$logdir = $ScriptRoot + "\UltimateDeployLogs\"
$transcriptfilename = $logdir + $StartTime + "ultimate-deploy_Transcript.log"
$logfilename = $logdir + $StartTime + "ultimate-deploy.log"
#initializing maaaany counters
[int]$total_vms = 0
[int]$processed_vms = 0
[int]$total_clusters = 0
[int]$total_errors = 0
[int]$total_dplfail = 0
[int]$total_pwrok = 0
[int]$total_pwrfail = 0
[int]$total_custstart = 0
[int]$total_custok = 0
[int]$total_custfail = 0
#test for log directory, create if needed
if ( -not (Test-Path $logdir)) {
New-Item -type directory -path $logdir | out-null
}
#start PowerShell transcript
#Start-Transcript -Path $transcriptfilename
#load PowerCLI snap-in
$vmsnapin = Get-PSSnapin VMware.VimAutomation.Core -ErrorAction SilentlyContinue
$Error.Clear()
if ($vmsnapin -eq $null) {
Add-PSSnapin VMware.VimAutomation.Core
if ($error.Count -eq 0) {
write-and-log $logfilename "PowerCLI VimAutomation.Core Snap-in was successfully enabled." 0 "terse"
}
else{
write-and-log $logfilename "Could not enable PowerCLI VimAutomation.Core Snap-in, exiting script" 1 "terse"
Exit
}
}
else{
write-and-log $logfilename "PowerCLI VimAutomation.Core Snap-in is already enabled" 0 "terse"
}
if ($true) {#if ($env:Processor_Architecture -eq "x86") { #32-bit is required for OS Customization Spec related cmdlets
if (($vmsnapin.Version.Major -gt 5) -or (($vmsnapin.version.major -eq 5) -and ($vmsnapin.version.minor -ge 5))) { #check PowerCLI version
#assume everything is OK at this point
$Error.Clear()
#sanitize input a little
$vms2deploy = Import-Csv -Path $csvfile
$vms2deploy = $vms2deploy | where-object {($_.name -ne "") -and ($_.template -ne "") -and ($_.oscust -ne "") -and ($_.cluster -ne "")} | sort-object name -unique
$total_vms = $vms2deploy.count
#anything still there - let's deploy!
if ($vms2deploy) {
#we will start one background job per unique cluster listed in .csv file
$host_clusters = $vms2deploy | sort-object cluster -unique | select-object cluster
$total_clusters = $host_clusters.count
#connect vCenter from parameter, we need to save credentials, to pass them to background jobs later on
$credentials = $Host.UI.PromptForCredential("vCenter authentication dialog","Please provide credentials for $vCenterServer", "", "")
Connect-VIServer -Server $vCenterServer -Credential $credentials -ErrorAction SilentlyContinue | Out-Null
#execute only if connection successful
if ($error.Count -eq 0){
#use previously defined function to inform what is going on, anything else than "terse" will cause the message to be written both in logfile and to screen
Write-And-Log $logfilename "vCenter $vCenterServer successfully connected" $error.count "terse"
#measuring execution time is really hip these days
$stop_watch = [Diagnostics.Stopwatch]::StartNew()
#fire a background job for each unique cluster
foreach ($cluster in $host_clusters) {
$vms_in_cluster = $vms2deploy | where-object { $_.cluster -eq $cluster.cluster }
$logfile = $logdir + $StartTime + $cluster.cluster + "-DeployJob.log"
$progressfile = $logdir + $cluster.cluster + "-progress.csv"
Write-And-Log $logfilename "Dispatching background deployment job for cluster $($cluster.cluster)" 0 "full"
$jobs_tab += @{ $cluster.cluster = start-job -name $cluster.cluster -scriptblock $deployscriptblock -argumentlist $vCenterServer, $credentials, $vms_in_cluster, $logfile, $progressfile }
}
#track the job progress + "ornaments"
do{
#do not repeat too often
Start-Sleep -Seconds 20
Write-And-Log $logfilename "Pooling background deployment jobs" -1
$running_jobs = 0
$total_pwrok = 0
$total_dplfail = 0
$total_pwrfail = 0
$total_custstart = 0
$total_custok = 0
$total_custfail = 0
foreach ($cluster in $host_clusters){
if ($($jobs_tab.Get_Item($cluster.cluster)).state -eq "running") {
$running_jobs++
}
$progressfile = $logdir +$cluster.cluster + "-progress.csv"
$jobs_progress = Import-Csv -Path $progressfile
$total_pwrok += $jobs_progress.PWROK
$total_dplfail += $jobs_progress.DPLFAIL
$total_pwrfail += $jobs_progress.PWRFAIL
$total_custstart += $jobs_progress.CUSTSTART
$total_custok += $jobs_progress.CUSTOK
$total_custfail += $jobs_progress.CUSTFAIL
}
#display different progress bar depending on stage we are at (if any customization started, show customization progress, in this way we always show "worst case" progress)
if ($total_custstart){
$processed_vms = $total_custok + $total_custfail
write-progress -Activity "$running_jobs background deployment jobs in progress" -Status "Percent complete $("{0:N2}" -f (($processed_vms / $total_pwrok) * 100))%" -PercentComplete (($processed_vms / $total_vms) * 100) -CurrentOperation "VM OS customization in progress"
}
else {
$processed_vms = $total_pwrok + $total_pwrfail + $total_dplfail
write-progress -Activity "$running_jobs background deployment jobs in progress" -Status "Percent complete $("{0:N2}" -f (($processed_vms / $total_vms) * 100))%" -PercentComplete (($processed_vms / $total_vms) * 100) -CurrentOperation "VM deployment in progress"
}
Write-And-Log $logfilename "Out of total $total_vms VM deploy requests there are $total_pwrok VMs successfully powered on, $($total_pwrfail + $total_dplfail) failed." $($total_pwrfail + $total_dplfail) "full"
Write-And-Log $logfilename "Out of total $total_pwrok successfully powered on VMs OS Customization has started for $total_custstart VMs, succeeded for $total_custok VMs, failed for $total_custfail." $total_custfail "full"
#until we are out of active jobs
} until ($running_jobs -eq 0)
#time!
$stop_watch.Stop()
$elapsed_seconds = ($stop_watch.elapsedmilliseconds)/1000
$total_errors = $total_pwrfail + $total_custfail + $total_dplfail
#farewell message before disconnect
Write-And-Log $logfilename "Out of total $total_vms VM deploy requests $total_pwrok VMs were successfully powered on, $($total_pwrfail + $total_dplfail) failed, $($total_vms - $total_pwrok - $total_pwrfail - $total_dplfail) duplicate VM names were detected (not deployed)." $($total_pwrfail + $total_dplfail) "full"
Write-And-Log $logfilename "Out of total $total_pwrok successfully powered on VMs OS Customization has been successful for $total_custok VMs, failed for $total_custfail." $total_custfail "full"
Write-And-Log $logfilename "$($host_clusters.count) background deployment jobs completed in $("{0:N2}" -f $elapsed_seconds)s, $total_errors ERRORs reported, exiting." $total_errors "full"
#disconnect vCenter
Disconnect-VIServer -Server $vCenterServer -Confirm:$false -Force:$true
}
else{
Write-And-Log $logfilename "Error connecting vCenter server $vCenterServer, exiting" $error.count "full"
}
}
else {
Write-And-Log $logfilename "Invalid input in $csvfile file, exiting" 1 "full"
}
}
else {
write-and-log $logfilename "This script requires PowerCLI 5.5 or greater to run properly" 1 "full"
}
}
else {
write-and-log $logfilename "This script should be run from 32-bit version of PowerCLI only, Open 32-bit PowerCLI window and start again" 1 "full"
}
#Stop-Transcript
WoW! That was long! A new record of 486 lines!
But seriously – control part of the script is contained between Line 325 and Line 486, this is where input is sanitized and background jobs are dispatched.
From Line 413 to the very end the script is only pooling these jobs for progress and displaying information about it.
All the “deployment magic” happens in a humongous script-block defined between Line 97 and Line 320, so lets focus on that first.
Because this script-block is started as separate PowerShell (not PowerCLI!) process we first have to (and this time I mean it) load the PowerCLI snapin, then connect to our vCenter Server (because background job doesn’t inherit this connection).
As you can see vCenter address and log-on credentials (gathered from user upon script start-up) are passed to script-block as parameters. The three remaining parameters are array of VMs to be deployed in given cluster and locations of log and progress tracking files. The helper object to track job progress is defined between Line 100 and Line 110.
Now, I was trying to “think big” when writing this script, but I’m also a bit of a “control freak”, so I decided against just firing all the VMs we want to deploy at once. You can of course start 100 or more new-vm tasks asynchronously and let vCenter sort the load out, but well… I prefer to do it in smaller chunks, with cluster capacity in mind if possible. That’s why I’ve defined two while loops that make sure each available host in cluster is deploying at most one VM at any given moment this script-block is running. The loops continue until we run out of VMs from input. You can say this slows the whole process down, but in my opinion it is better to be safe than sorry.
When your cluster runs out of capacity for example (because you requested too many VMs to be deployed) and DRS is not able to power on any VMs more (I actually created such condition for testing purposes, you can see that in screenshots below), the deployment will just stop in a controlled way, without overloading vCenter or anything, this approach also makes control of deployment and OS Customization faster and less resource greedy.
Last but not least – it is really easy to change this code to start more than one VM deployment per host ;).
As for deployment control – I use classic method described by Luc Dekens (who else? 😉 ) ages ago. Between Line 150 and Line 202 a “chunk” of new-vm tasks is started asynchronously, information about these tasks is saved into a hash table, using task id as hash and name of deployed VM as value.
Further on (between Line 205 and Line 225) list of recent tasks is retrieved from vCenter and matched against our saved ids. If there is a match and the task was successful we power on the machine (to let OS Customization process begin) and remove this task from our table (removing is also done for all failed tasks).
This part loops until we run out of deployment tasks, then new “chunk” is started.
Only after we deploy (and hopefully power on) all requested VMs, we switch to track the progress of OS Customization inside the guests. If your batch is on the larger side, there is a good chance that some of the OS Customizations will complete before we even check ;). This part of script is “inspired” (OK, I almost copy-pasted it completely 😉 ) by excellent post of VMware’s Vitali Baruh. Although it looks somewhat complicated (defining a script-block inside script-block to control main loop…) the idea is not that difficult to perceive.
Basically for each VM that powered-on successfully (we don’t care about failed ones anymore) we search vCenter events for “CustomizationStarted”, “CustomizationSucceeded” and “CustomizationFailure” events. The loop repeats every 10 seconds (like all loops in this script-block) until we are out of VMs or time-out (fixed to 7200 seconds or two hours) elapses.
I would like to stress-out that this time-out is only for OS Customizations part (we all know how many things can go wrong there, right?), by no means will it disrupt “deploy and power on” part of the script-block.
And that’s basically it for the “worker horse” of this script.
I have to admit I cheated a little in the main loop that displays script progress…
As you can see every major loop inside the script-blog dumps current progress indexes (I define 6 of them between Line 100 and Line 110) to a .csv file inside the script log directory.
The control loop in main script section picks-up these indexes for all dispatched background jobs and estimates overall progress (or at least tries to do so 😉 ).
You’re free to say it is neither most elegant nor the fastest way to track progress of background jobs, but it just does the trick and I’m not too worried that short write sequence every ten seconds will kill your storage subsystem ;).
In the first stage of workflow the progress is calculated as proportion of sum of VMs that powered on successfully (or failed across all background tasks) against the grand total of VM deployment requests (from CSV file), so your PowerCLI window might look like that:
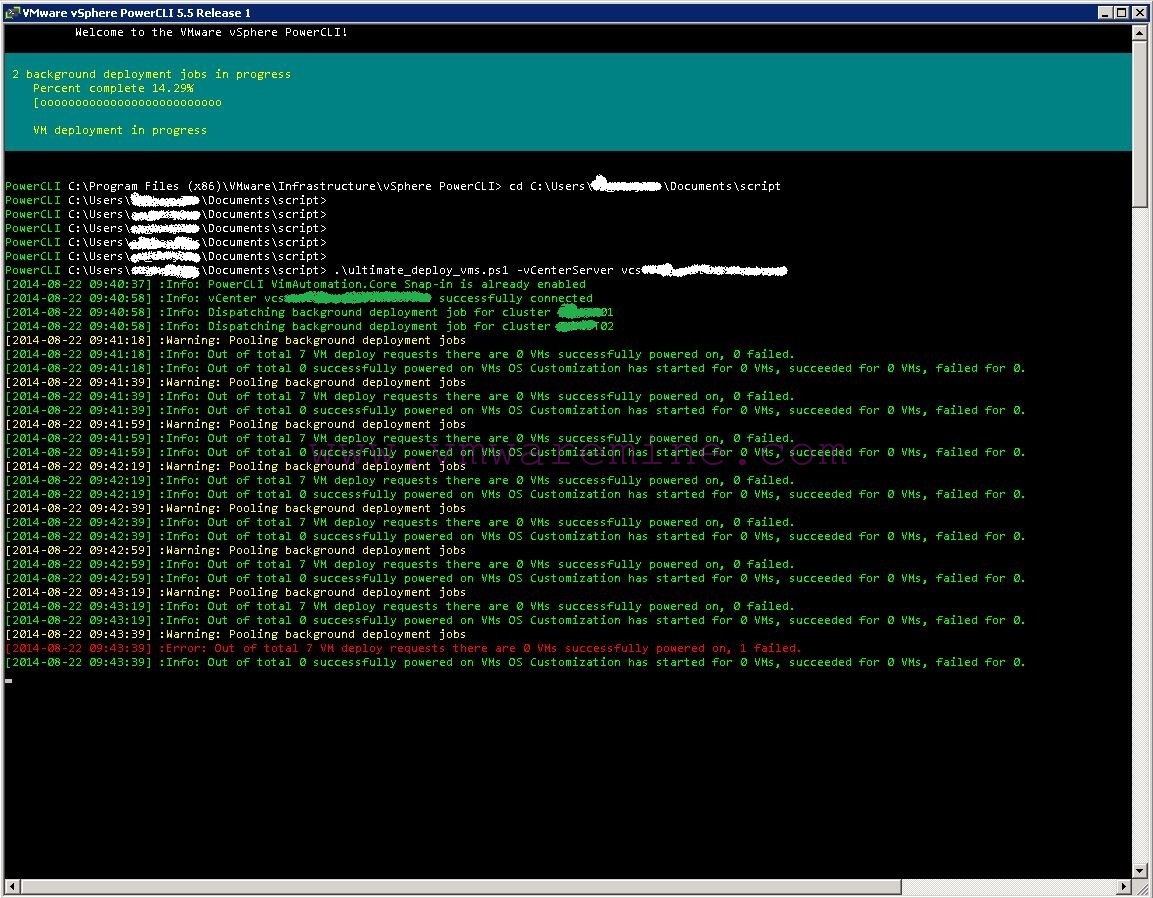
Then, if script detects that OS Customization has started inside any of the background jobs (CUSTSTART index greater than 0), it switches to displaying progress as sum of successful and failed customizations compared to total of successfully powered on VMs.
You can see that “current activity” field displayed by write-progress cmdlet changes from “VM deployment in progress” to “VM OS Customization in progress”.
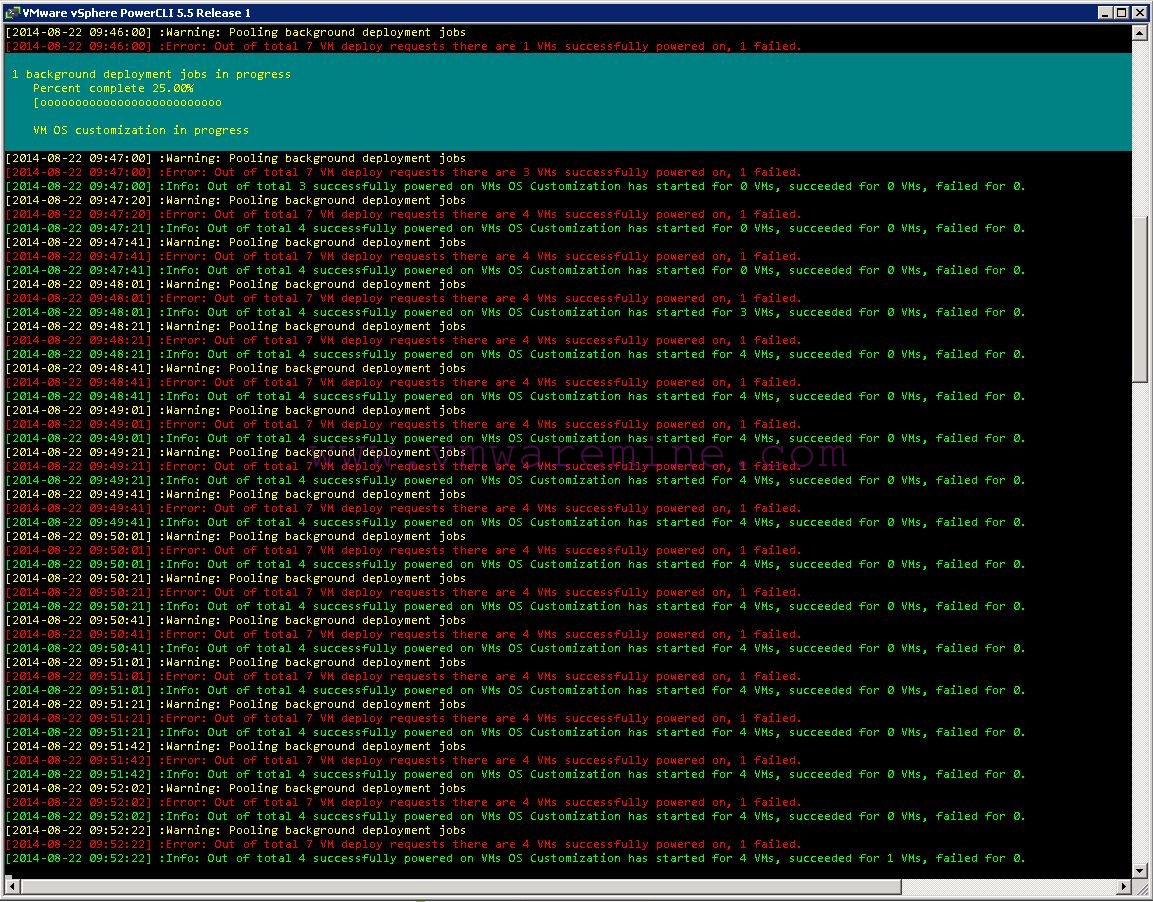
This might have funny effects, in situations where you, for example, deploy one “monster VM” in (say) “server cluster” and a bunch of small VMs in (say) “vdi cluster”.
Probably many of the small VMs will power on before “the monster”, so your indicated progress will be soaring, then once “monster VM” starts OS Customization, the progress will suddenly drop to zero…
To my defense: this approach always shows “worst case” scenario, so you will never see progress bar stuck at 100% for hours and such unexpected behavior can be somewhat amusing while you wait for jobs to complete ;).
I call this script “ultimate” for two reasons. First of all – as a joke of course :D.
Secondly – I really have no idea how to make it more complex… ah wait… I could introduce additional safety checks (like free diskspace in datastores, or load on host clusters) or I could introduce customization of vCPU and vRAM assignments (so that VMs could be deployed with resources different from the ones fixed in template)…
Sky is (almost) the limit and maybe I should come back to this script once again in the future .
(Read: after I’m back from holiday 😉 ).
That’s it for now. I hope you will find this script useful, feel free to share or provide your feedback!
<Update, August 29th, 2014>
I just noticed that (by mistake) I posted “very early” version of this script…
While I create a “very advanced hash-table” in Line 395 I do not make any use of it (at least not in the version originally posted) 🙁
Instead I just did a rudimentary query (Line 402 of “early script”) for all background jobs that are running (which in some cases – like “orphaned” background jobs – can lead to unexpected results).
This was legacy from the time I struggled a bit with controlling these jobs, so I corrected it and now you see a really “elegant” way of querying only the jobs we started between Line 409 and Line 421.
Enjoy!
</Update>

Excellent script! One note – moving to PowerCLI 5.5 R2 would alleviate the need to use a 32bit PowerShell console.
Hi.. How would someone run this script especially if they are a beginner at scripting..
I am trying to use this for mass builds but it keeps using the same host names and not all of them. I use names sequentially and it picks only a few repeatedly and skips the others entirely. For example, guests named ABCDCTX101 – ABCDCTX160 would be in the CSV and it will choose 108, 109, and 122 and start them off. It will try the same three names every time and all of them fail. If I use less machine than the number of the hosts in a cluster I get a divide by 0 error. Any help would… Read more »
Hey,
Looks really good I’m going to try it with powercli 5.8 R1.
Did you think to introduce also the portgroup configuration?
Hi! Thanks for the script, would appreciate some help, I have gone through your instruction but all I am seeing is : [2014-10-21 18:05:04] :Info: Out of total 4 VM deploy requests there are 0 VMs successfully powered on, 0 failed. [2014-10-21 18:05:04] :Info: Out of total 0 successfully powered on VMs OS Customization has started for 0 VMs, succeeded for 0 VMs, failed for 0. The script has been running for over an hour! Anything I should be looking at? The input CSV has the esx hostname and the folder name is where I want the VM’s to land… Read more »
Hi,
It must be a little problem for customization on linux systems.
The script poweron the VM but never customatize it and keep on a infinite loop on messages:
[2014-10-28 10:51:00] :Info: Out of total 2 VM deploy requests there are 2 VMs successfully powered on, 0 failed.
[2014-10-28 10:51:00] :Info: Out of total 2 successfully powered on VMs OS Customization has started for 0 VMs, succeeded for 0 VMs, failed for 0.
Any idea?
Hi! First of all great script! I’m running into an issue where it keeps saying X# of VMs have failed while the vmware files are being copied. [2014-11-05 10:52:33] :Error: Out of total 2 VM deploy requests there are 0 VMs successfully powered on, 2 failed. After they finish copying and start up it still says X# have failed but the same number successfully powered on: [2014-11-05 10:59:35] :Error: Out of total 2 VM deploy requests there are 2 VMs successfully powered on, 2 failed. then never continues from there and gives an error: ——- Write-Progress : Cannot validate argument… Read more »
Everytime I try to run it I just get the following
Attempted to divide by zero.
At U:scriptsdeployvms.ps1:361 char:31
+ “{0:N2}” -f (($processed_vms / <<<< $total_v
+ CategoryInfo : NotSpecified: (:)
+ FullyQualifiedErrorId : RuntimeException
Attempted to divide by zero.
At U:scriptsdeployvms.ps1:361 char:203
+ write-progress -Activ
ployment jobs in progress" -Status "Percent com
_vms / $total_vms) * 100))%" -PercentComplete (
ms) * 100) -CurrentOperation "VM deployment in
+ CategoryInfo : NotSpecified: (:)
+ FullyQualifiedErrorId : RuntimeException
I got this working, looks like when you install PowerCLI you really do need to reboot 😛 One question. is there away to assign multiple IPs to a new VM? I am deploying 300 web servers with 6 IPs each atm. Currently, I am using a fairly simple script on the C drive which asks you to manually input the last octet of the IP. It is a time saver, but a fully automated method would be more more preferable.
Hi Sebastian, First, great script but we are missing something. As you suggested, we modified the script as we do not run datastore cluster, so we changed two locations to get-cluster. After initiating the script, we are prompted to connect to the server, that succeeds. And then we get the following [2015-02-04 02:57:27] :Info: vCenter v1173vmvc01 successfully connected [2015-02-04 02:57:27] :Info: Dispatching background deployment job for cluster 1173-Cluster [2015-02-04 02:57:48] :Warning: Pooling background deployment jobs [2015-02-04 02:57:48] :Info: Out of total 2 VM deploy requests there are 0 VMs successfully powered on, 0 failed. [2015-02-04 02:57:48] :Info: Out of total… Read more »
Sebastian,
I also neglected to say our CSV contains the following
name,template,oscust,cluster,folder,datastore,ip,mask,gw,dns1,dns2
wanted to make sure that was correct since we modified the datastorecluster to datastore
thanks for any help you can provide
moe
Also just noticed the DeployJob.log has the following
[2015-02-04 03:56:11] :Info: vCenter vmvc01 successfully connected
[2015-02-04 03:56:12] :Info: Cloning OS customization for vmtest1
[2015-02-04 03:56:14] :Info: Starting async deployment for vmtest1
Cannot bind parameter ‘Datastore’. Cannot convert the “” value of type “System.
Management.Automation.PSCustomObject” to type “VMware.VimAutomation.ViCore.Types.V1.DatastoreManagement.StorageResource”.
First of all thanks for the Script but I am having some trouble deploying VMs from this script. I am using vpshere5.1U2 and power cli as 5.5r2patch1. when i am running script it clones customization and after that does nothing. I checked logs and this is what I see in the logs. Can you please help me with this.
“Cannot convert ‘System.Object[]’ to the type ‘VMware.VimAutomation.ViCore.Types.V1.Inventory.Template’ required by parameter ‘Template’. Specified method is not supported.”
Hi, first of all thanks for the script, but I am also having some trouble deploying VMs. I am using PowerCLI Version 5.8 R1. The script is trying to start the deployment, but is exiting after a few seconds (without showing any errors). Messages like “[2015-03-05 12:53:38] :Info: vCenter 192.168.154.7 successfully connected [2015-03-05 12:53:45] :Info: Cloning OS customization for TST-V-154-008-U [2015-03-05 12:53:46] :Info: Starting async deployment for TST-V-154-008-U Cannot validate argument on parameter ‘Datastore’. The argument is null or empty. Provide an argument that is not null or empty, and then try the command again. [2015-03-05 12:53:47] :Info: Cloning OS… Read more »
To fix “Cannot validate argument on parameter ‘Datastore'” errors, when not using datastore-clusters…Sebastian said to change two lines from “get-datastorecluster” to “get-cluster”, I found that it needs to be “get-datastore” instead, probably just mistyped the instructions.
After you change that on two lines, the vms will deploy to the datastore in the csv. Leave the csv field as datastorecluster, that is just a label referenced by the script.
I have been toying with this on and off today. Using the get-datastorecluster commands do not appear to work at all. Yes I have SDRS enabled clusters. Job fails with the following : Required property datastore is missing from data object of type VirtualMachineRelocateSpecDiskLocator Using the get-datastore command seems to work better but erroneous errors are thrown even though the job is working fine: [2015-04-10 13:23:55] :Error: Out of total 2 VM deploy requests there are 2 VMs successfully powered on, 2 failed. Also the timestamps reported in the logs are not consistently formatted: [2015-04-10 13:05:16] :Info: Starting async deployment… Read more »
Thanks for putting this together. I’m running powercli version 5.8. I made the cluster change in the notes below. PowerCLI is crashing when I run the script:
Problem signature:
Problem Event Name: APPCRASH
Application Name: powershell.exe
Application Version: 6.1.7600.16385
Application Timestamp: 4a5bc7f3
Fault Module Name: KERNELBASE.dll
Fault Module Version: 6.1.7601.18409
Fault Module Timestamp: 5315a05a
Exception Code: e053534f
Exception Offset: 000000000000940d
OS Version: 6.1.7601.2.1.0.272.7
Locale ID: 1033
The internet doesn’t really have a desciption for this error. Any ideas?
Everytime I try to run this script it says that the VM names are duplicate so they won’t deploy. Each time for testing I change the name and when I test deploying by just doing a new-vm from the command line outside of your script it does not fail at all. Any help would be appreciated.
Brilliant script I have an issue that it thinks the new vms already exist any ideas ? [2015-08-27 10:31:27] :Info: vCenter ch-vcntr5-2k8 successfully connected [2015-08-27 10:31:27] :Info: Dispatching background deployment job for cluster Cluster1 [2015-08-27 10:31:50] :Warning: Pooling background deployment jobs [2015-08-27 10:31:50] :Info: Out of total 2 VM deploy requests there are 0 VMs successfully powered on, 0 failed. [2015-08-27 10:31:50] :Info: Out of total 0 successfully powered on VMs OS Cust omization has started for 0 VMs, succeeded for 0 VMs, failed for 0. [2015-08-27 10:32:10] :Warning: Pooling background deployment jobs [2015-08-27 10:32:10] :Info: Out of total 2… Read more »
Nice script, Sebastian. I’m having an issue when deploying multiple VMs concurrently. So that only one VM is cloned from the template and until that VM is completed to include power on – then it moves to the next VM. However, at some point its stops deploying VMs. I noticed that vCenter is showing an error from the template: error caused by /vmfs/volumes/GUID/<>/<> Not sure what’s going on there. Secondly the next error I see in the powershell: “attempted to divide by zero” it doesn’t like “{0:N2}” -f (($processed_vms / ((( $total_vms> * 100) Which others have commented. Has there… Read more »
Found this from your post on LucD’s original post. I’m having the client task/server task issue you mentioned there (not using this script using something I’m writing myself).
Can you explain what you did to work around the problem you originally had and how this script avoids that issue?
Because I don’t see it and I’m very puzzled.
I got it to work to deploy concurrently the VMs. I went ahead and created a shell VM and pointed an existing vmdk (the old template).
Once this was done things started to go as it should, with the exception of the “Attempted to divide by zero” error.
when I run it I get the following error
[2015-11-18 15:24:07] :Info: PowerCLI VimAutomation.Core Snap-in was successfully enabled.
[2015-11-18 15:24:07] :Error: This script requires PowerCLI 5.5 or greater to run properly
and then it quits, i have powershell 4.0 and PowerCLI 6.0 installed.
I am having an issue where no errors come up and I don’t know what parameters to correctly type into the CSV. I am only adding in a single host during testing for now. I am trying: name,template,oscust,cluster,folder,datastorecluster,ip,mask,gw,dns1,dns2 shockwavecsVM,CentOSDevTemplate64bit,none,"hqvcenter1 - Cluster",hqvcenter1,"RAID10-Slow-VM2",none,none,none,none,none Notes on fields: “cluster” “hqvcenter1 – Cluster” is the name of my 3 node cluster “datastorecluster” – I don’t have a datastore cluster. The RAID10-Slow-VM2 is the name of a datastore that is available to the entire 3 node cluster. – I have already changed the powershell script to say “get-datastore” instead of “get-datastorecluster” in the 2 locations. “folder”… Read more »
I was wondering if you can help with the following error. I am trying to add just two VMs for testing and I don’t know what I’m doing wrong here. “409 char:23 $jobs_tab +=$cluster.cluster” A null key is not allowed in a hash literal. “426 char:13 if ($jobs_tab.Get_Item($cluster.cluster>>.state -eq “running” You cannot call a meth on a null-valued express “447 char:115 Attempted to divide by zero. Log files [2016-02-22 16:05:22] :Info: vCenter uwhc-vc02 successfully connected [2016-02-22 16:05:41] :Info: Cleaning-up cloned OS customizations [2016-02-22 16:05:14] :Info: Dispatching background deployment job for cluster [2016-02-22 16:05:34] :Info: Out of total 0 VM deploy… Read more »
I’m curious, has anyone reading been able to modify this script to deploy to a specific host instead of to a cluster? My environment has 2 unclustered hosts at a remote datacenter that we use as a lab environment. It would be great to use this script for creating a bunch of test systems. I’m a still quite the novice when it comes to PowerShell.
If you are still having the Divide by Zero issue…. Follow what Cory said….. Just add more than 1 test VM in your .CSV file and that will work… Also, if you are not using Datastore Clusters…. replace in the source code where ever there is ‘Get-DatastoreCluster’ to -> ‘Get-Datastore’ and leave the CSV header the same… Thanks Matt & Cory for the advice.
So far I have been very unlucky to use this. I am powercli 5.5 R2 on windows2008 R2 system; connecting to a VC with DRS enabled on storage and cluster nodes with following vms2deploy.vcs vm1-jaw,Template_Win2012-R2-Std-CL02,Server 2012 R2 Std (Enterprise License),DHESXCL02,Infrastructure,DH-XIOCL02,10.55.4.45,255.255.255.0,10.25.4.1,10.55.4.38,10.55.4.102 vm2-jaw,Template_Win2012-R2-Std-CL02,Server 2012 R2 Std (Enterprise License),DHESXCL02,Infrastructure,DH-XIOCL02,10.55.4.46,255.255.255.0,10.25.4.1,10.55.4.38,10.55.4.102 I keep getting these errors and nothing happens; scritp does not log why its failling .Vm-batchdeployment.ps1 cmdlet Vm-batchdeployment.ps1 at command pipeline position 1 Supply values for the following parameters: vCenterServer: 10.55.90.220 [2016-05-06 11:10:35] :Info: PowerCLI VimAutomation.Core Snap-in is already enabled WARNING: There were one or more problems with the server certificate for the server… Read more »
I too am getting the “duplicate VM names were detected (not deployed).” message.
Can the script be edited to allow configuration of a second vNIC?
Thanks for amazing script, kindly advise what modification i need to do if i am using this script for one cluster. Please advise.
Hi
How to insert installation scriptblock to install roles and configuration on Windows VM:s?