The title of this post is obviously inspired by (rather epic) movie of “Black Hawk Down”.
Now that you know it’s gonna be some serious business, here comes a
Disclaimer: Procedure described below is derived from author’s own and limited experience, being of such origin it should not be treated as a supported or recommended way of troubleshooting APD / PLD condition. Instead, it is provided as-is and no warranty expressed or implicit is given, that it will yield positive results in your environment. Use it at your own risk only!
A long time ago, in a galaxy far, far away, where I happened to support vSphere Infrastructure, a deduplicated storage volume was serving three LUNs, purposedly used as VMFS datastores.
One night it happened so, that a single “monster VM” located on that volume acquired extraordinarily large amount of new data.
As a result VMDK files of this VM had to be inflated in the backend and before deduplication routine (that was scheduled to run asynchronously, every 60 minutes) kicked in, the volume ran out of disk space and storage backend logic decided to… take all three LUNs offline.
According to the official KB this is known as APD (All Paths Down) condition, so a transient issue with storage backend (and there is possibility to restore connection to affected LUN(s)) – as opposed to situation of complete LUN and/or array corruption, when we loss the device permanently (PDL condition, aka Permanent Device Loss).
The issue was indeed transient, my storage team colleagues just extended the backend volume (we were lucky, pardon, well prepared, to have some slack disk space), which immediately brought all three LUNs online.
After HBA rescan in respective vSphere DRS/HA cluster, these LUNs turned “green” almost instantly in vSphere Client.
Well… except for the hosts, where the affected VMs were actually running…
So I was in a situation, where LUNs were (back) online and visible by most of the hosts in the cluster, but a few vSphere hosts were unable to re-connect the three LUNs in question.
Since those were only the hosts where VMs from affected LUNs were running, my guess was it was result of some “outstanding I/Os” ending-up in “virtualization limbo”, when the datastores went offline w/o any warning.
Luckily I was able to retrieve a lot of information from the vSphere Client itself:
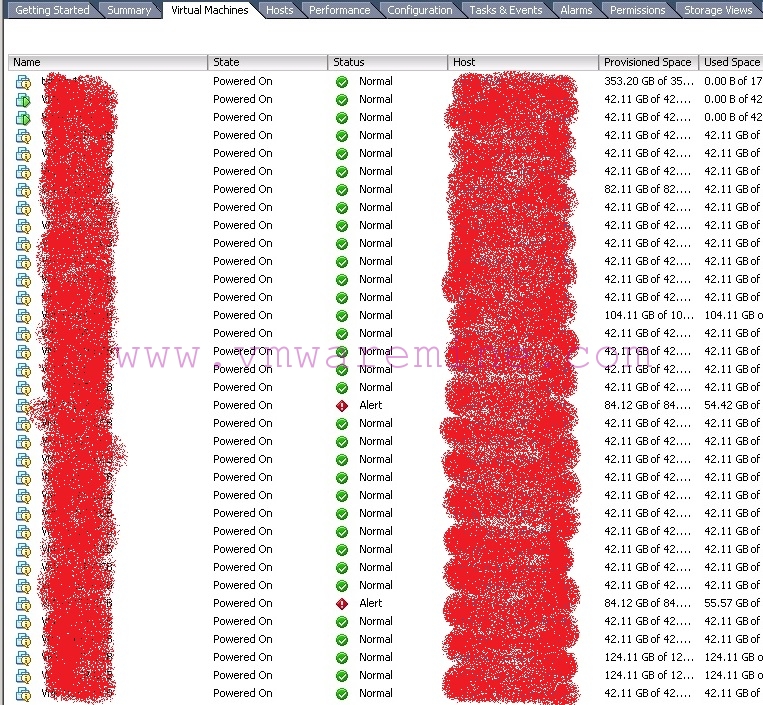
APD impact on VMs as seen in vSphere Client
This is nothing else but default “Virtual Machines” view, where you can see all affected VMs and their respective hosts (I had to obfuscate VM and vSphere hosts names, hope you understand) 😉
I’m sure you can recognize the yellow “exclamation mark” icon next to VM names – each of the VMs was waiting for the answer whether to “Retry” or “Abort” I/Os that timed out (when the LUNs were offline).
The problem was – neither of the answers was doing any good, VMs did not want to pick-up (“Retry”) I/O, nor give it up (“Abort”) completely.
They were all unresponsive and nothing I was trying from the host end (HBA rescans, restart of management agents) could change that.
Attempts to put affected hosts in “Maintenance mode” were of course futile (because of these unresponsive VMs that refused to vMotion, right?) and I couldn’t afford just to reboot the hosts, cause that would have killed other workloads (from other datastores) residing there…
I had no choice but to go “medieval” with this issue and SSH to each host affected just to:
~ # ps | grep AffectedVMName 12084 vmm0:AffectedVMName 12086 vmm1:AffectedVMName 12087 vmm2:AffectedVMName 12088 vmm3:AffectedVMName 12089 12073 vmx-vthread-7:AffectedVMName /bin/vmx 12278 12073 vmx-vthread-8:AffectedVMName /bin/vmx 12279 12073 vmx-mks:AffectedVMName /bin/vmx 12280 12073 vmx-svga:AffectedVMName /bin/vmx 12281 12073 vmx-vcpu-0:AffectedVMName /bin/vmx 12282 12073 vmx-vcpu-1:AffectedVMName /bin/vmx 12283 12073 vmx-vcpu-2:AffectedVMName /bin/vmx 12284 12073 vmx-vcpu-3:AffectedVMName /bin/vmx ~ # kill -9 12281
What I did there, was to filter (ps | grep AffectedVMName) all processes (pardon, worlds) of affected VM on the current host (I knew which of affected VMs were running on which vSphere host from the vSphere Client – see picture above), then ruthlessly ( kill -9 ) terminate the world representing vCPU0 of each affected VM.
The procedure described in official KB (that I discovered a few days later) is quite similar, just a little more elegant, using fancy esxcli syntax and stuff ;).
I was worried, that after terminating all the unresponsive VMs, I will have to follow official path, remove all of them from vCenter inventory, then add it back, but…
To my pleasant surprise HA kicked-in and automatically restarted each and every VM, that I killed manually (and I didn’t have “VM monitoring” enabled in this cluster!).
VMs were of course restarted on the hosts that already had the LUNs re-connected, so I knew “how” this happened, but it was still kind of mystery to me, why fdm daemon triggered HA restart, after event that was not really a “host failure”.
I will let you know, if I find out anything ;).
Once all affected VMs were restarted it was enough just to “Rescan All…” (Storage Devices and VMFS Datastores) from vSphere Client to re-connect the three LUNs in question on the stubborn hosts.
Nevertheless (better safe, than sorry) I followed the VMware recommendation and to make sure there were no loose ends left, I ran a rolling reboot (first “Maintenance Mode”, of course) of all vSphere hosts in the affected cluster.
This is how I handled APD, when it struck me one starry night, I hope you will find this post useful, feel free to share it and provide your feedback!
(Just remember the disclaimer above ;).

Hey,
the HA restart action is triggered by the property runtime.cleanPowerOff. When you shutdown power off the VM manually it is set to true and an HA restart will not happen. When you kill the process manually or by the PDL feature it will be set to false and the HA restart will be initiated.
//Magnus