Q: How many disks types you know?
A: Two. Those already broken and those will fail soon 🙂
How Nutanix AOS handle disk failures? Nutanix AOS has build in, out of the box self healing capabilities (no no, it does not heal the disk, … yet 😉 ). Nutanix AOS monitor all hardware components, including disks (both SSD and HDD). For disk monitoring, Nutanix AOS use S.M.A.R.T for proactive disk failure detection. When Nutanix AOS detects symptoms on disk which my lead to disk failure. Nutanix AOS stops writing any new data to disk. Immediately after failure detection, Curator scan occur. It scans Cassandra (it is Nutanix metadata) and checks what data need to be re-replicated. At eh end, Hades puts disk into offline to prevent further read and writes from\to disk.
In addition, as every modern system should do, Nutanix AOS informs admins about disk failure by rising alert in Prism. If you have SNMP or SMTP alerts configured, you will get info over monitoring system or email too. There is a Pulse services running on every Nutanix cluster. If it is enabled and configured to send cluster state to Nutanix support, then Support Request ticket will be open on your behalf and Nutanix support Engineers will be in touch with you shortly.
So, what do you have to do when you replace disk in Nutanix cluster. Nothing (apart of swapping disks, of course 🙂 ). Nutanix AOS will take care of everything. If you want, you can monitor process in Prism or by grabbing hades logs.
Hades is a process responsible for monitoring disks states and making disk online or offline.
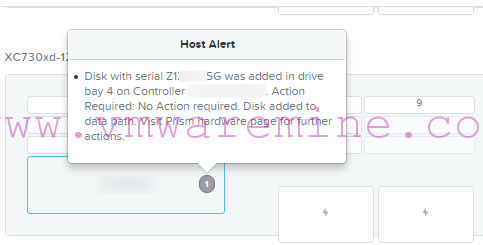
New disk information in Prism
Entries in Hades.out logs shows new disk was detected and succesfully added to pool of disks.
nutanix@NTNX-node-A-CVM:~$ less ~/data/logs/hades.out 2016-09-14 09:26:16 INFO disk_manager.py:6977 Successfully updated the Zeus configuration with disk configuration changes 2016-09-14 09:26:16 INFO disk_manager.py:7326 Killing the local stargate 2016-09-14 09:26:16 INFO disk_manager.py:2899 Disk /dev/sdj with serial XXXXXXXX is successfully added to cluster 2016-09-14 09:26:16 INFO disk_manager.py:4085 Led off request for disks ['/dev/sdj'] 2016-09-14 09:26:16 INFO disk_manager.py:4311 Running LED command: '/usr/local/nutanix/cluster/lib/sg3utils/bin/sg_ses --index=0,4 --clear=ident /dev/sg10' 2016-09-14 09:26:16 INFO disk_manager.py:4311 Running LED command: '/usr/local/nutanix/cluster/lib/sg3utils/bin/sg_ses --index=0,4 --clear=fault /dev/sg10' nutanix@NTNX-node-A-CVM:~$
That is it. Now, new disk is a part of disk pool and it is available for writing data.

Hi Artur, what are the Do’s and Dont’s regarding the NutanixManagementShare container which is created by default upon creating a cluster?
Is there a limit to its size?
Hi Ernes,
Is it brand new deployment or re-purpose of existing cluster?
Can you ping all the CVM’s IP’s from the CVM you are executing command? Are you 100% sure that CVM’s are not a part of another cluster?